Khronos Data Pump for Historians provides a powerful utility to push high-fidelity historian data to a remote MS SQL Server, either in the Cloud, at a remote location, or on-premise. It ensures that all new data, and historically stored data, is pushed to the target database, and caters for buffered data collection, late-bound data collection, network outages, and system outages. The pump runs as a Windows Service, and interacts with the OSI PI Web Service for high-speed data interaction.
Khronos Data Pump for Historians supports the following historians:
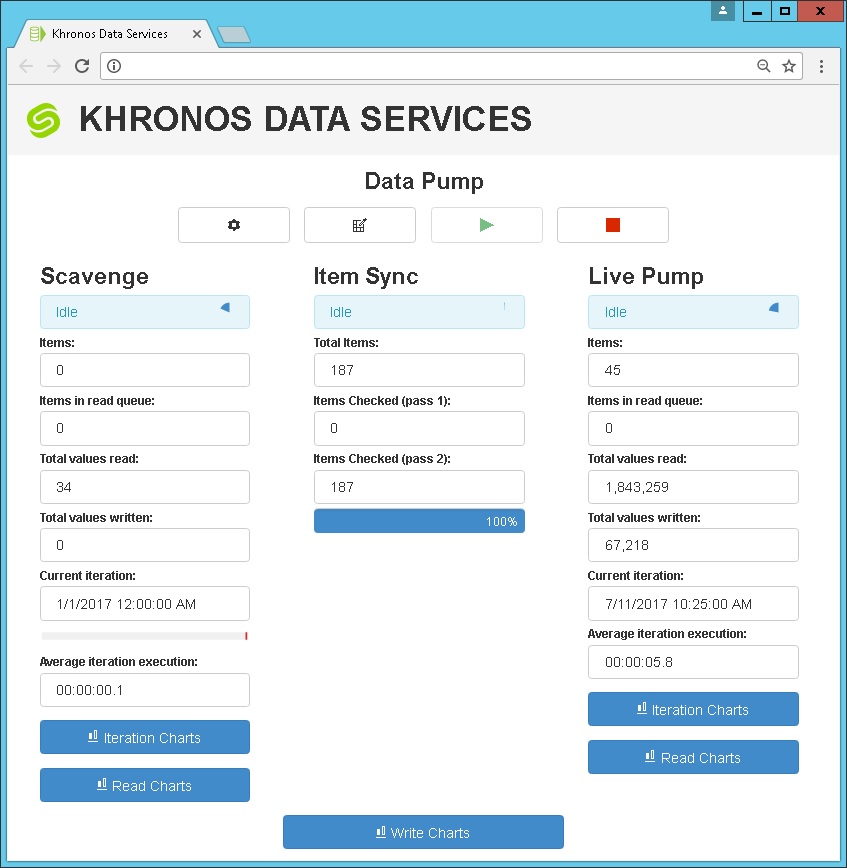
Khronos Data Pump will automatically synchronise a list of available points for pumping from the historian configuration. Customers can choose to push all historian points, or a sub-set of points. A configuration interface allows quick filtering of points by name or type to allow quick selection of which ones should be pumped. The system can be configured to automatically identify new points which are added to the historian, and automatically include them in future pump and scavenge cycles.
Khronos Data Pump performs two activities in parallel:
Tags which are selected for Pumping of new data will cause the pump to identify all new data recorded into the historian since the point was initially added into the pumped items list, and ensure that all new data samples since that point in time are pushed to the target database.
Tags which are selected for Scavenging of historical data will cause the pump to identify all historical data samples recorded in the historian prior to when the point was initially added into the pumped items list. The pump will retrieve all historical samples back through history (up until a user-defined date), and push the entire history for the point to the target database.
Khronos Data Pump for SQL Server provides a powerful facility to push on-premise data to the cloud or other remote data locations. it supports data transformation via SQL query prior to pumping, and has been specifically designed for cloud-based transfers with high-latency connections, but works just as well between local SQL Servers or over the WAN.
Khronos Data Pump for SQL Server is typically used to:
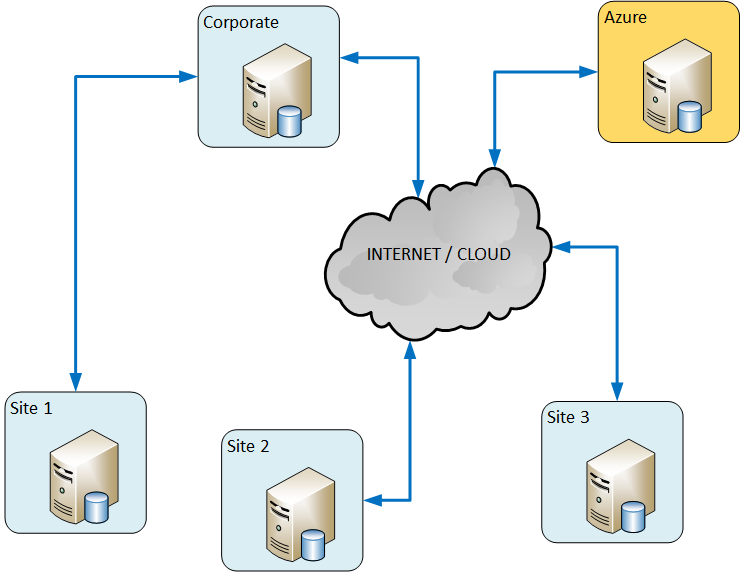
Example network for Khronos Data Pump for SQL Server
Khronos Data Pump for Excel provides a powerful facility to extract data from human-legible spreadsheets (rather than CSV style tables), and filter, interpret, transform, and push the extracted data into a SQL Database. This may be to on-premise databases or into the cloud or other remote locations. The pump supports multiple spreadsheets, worksheets, iteration cycles, and interpretation rulesets. It has been specifically designed for cloud-based transfers with high-latency connections, but works just as well to local SQL Servers or over the WAN.
Khronos Data Pump for Excel Spreadsheets is typically used to:
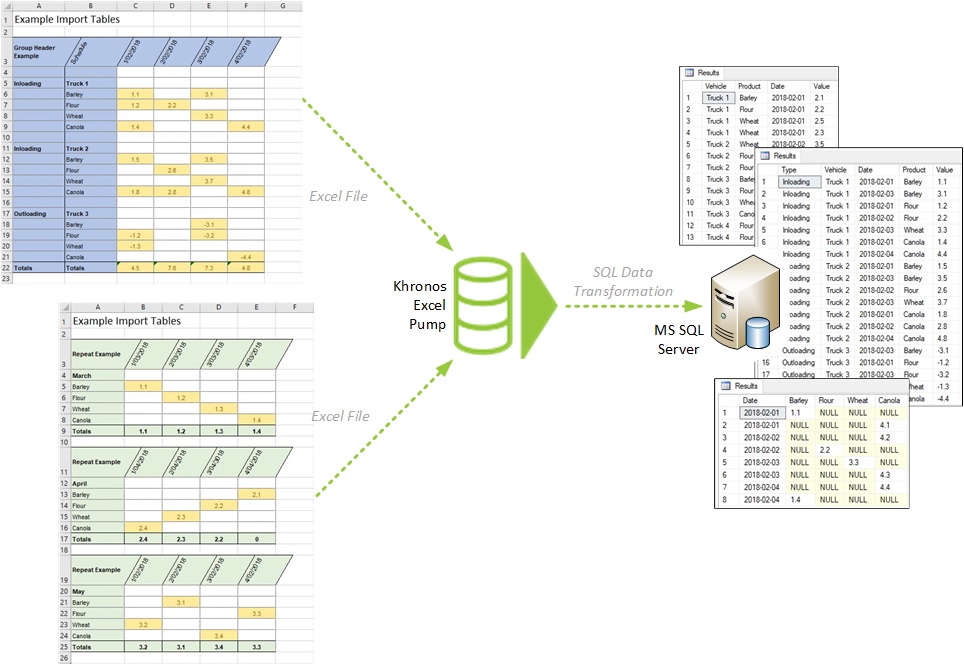
Example data flow for Khronos Data Pump for Excel Spreadsheet
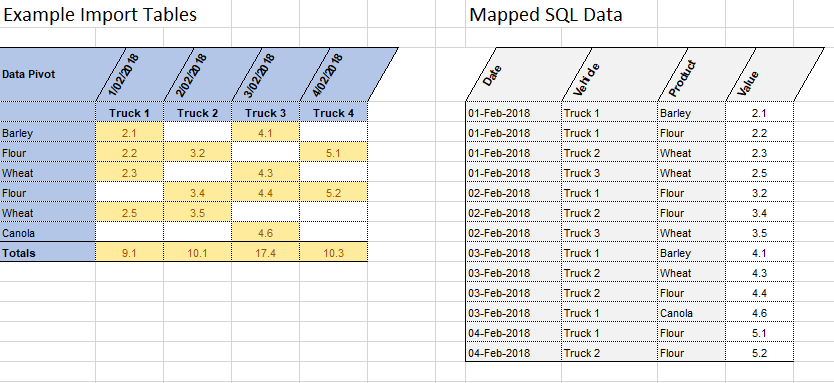
Khronos Excel Pump is configured to find data import blocks within your spreadsheet either by absolute cell reference, or by finding text (such as section headings) within the spreadsheet. When identifying import blocks by finding text values, the pump can repeat the operation to find multpiple import blocks with the same header and footer text, allowing you to configure a single import and have it process many data blocks one after the other. An example might be if you have similar data in separate sections of your worksheet for different production lines.
Khronos Excel Pump can replace text values from your spreadsheet with numerical values either via a static lookup list, or from a database lookup. This allows you to import data to a narrow, normalised table, using an Identity value for foreign-key relationships. The example is using this feature to replace product names with SQL Identity values during the import process.
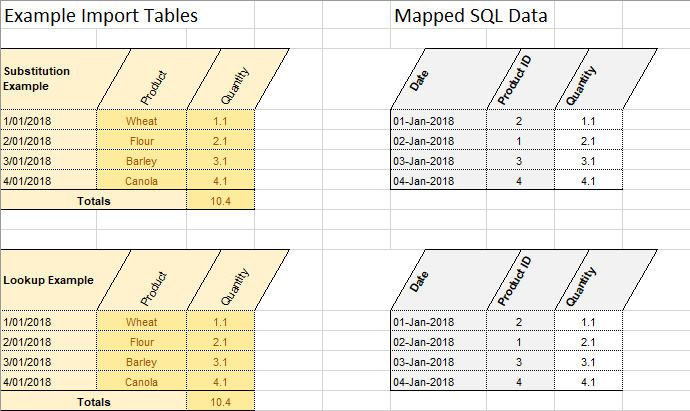
Khronos Excel Pump can be configured to pivot your wide, easy-to-read, spreadsheet data into narrow, normalised SQL tables. Generally, SQL tables are designed to leverage the power of SQL Server’s relational model, and therefore data tends to be stored in narrow, long tables rather than wide, short tables. The example shown is pivoting a couple of header rows into vertical columns (and these could also be replaced with lookup values to further improve the SQL storage design), and migrating the many values spread across the spreadsheet grid into a single column of values.
This aligns with SQL best-practice design standards and allows greater flexibility of expansion and querying. For example, if you stored the data in SQL Server the same way it appears in Excel, with a column for each truck, you would need to modify your SQL database each time you added another truck into the system. By storing the data in a narrow format, new trucks simply become new rows in the same table.